TIL on MON about DLS(1)
random hyperparameter tuning
coarse to fine
batch normalization
gamma
beta
batch norm
mini batch
Deep Learning Specialization[Course2]
- Coursera - Professor Andrew Ng, Stanford Univ.
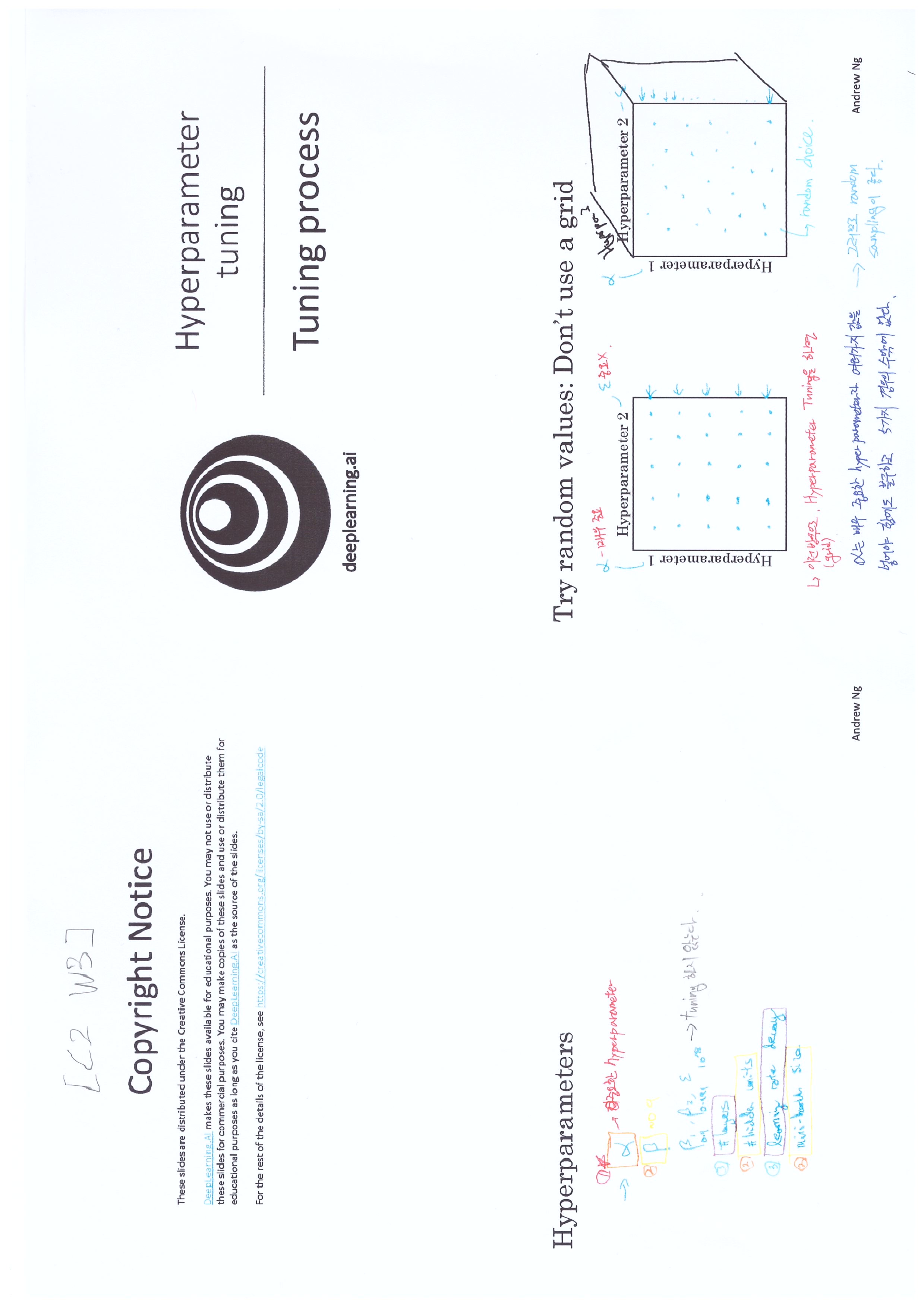
Note
random hyperparameter tuning
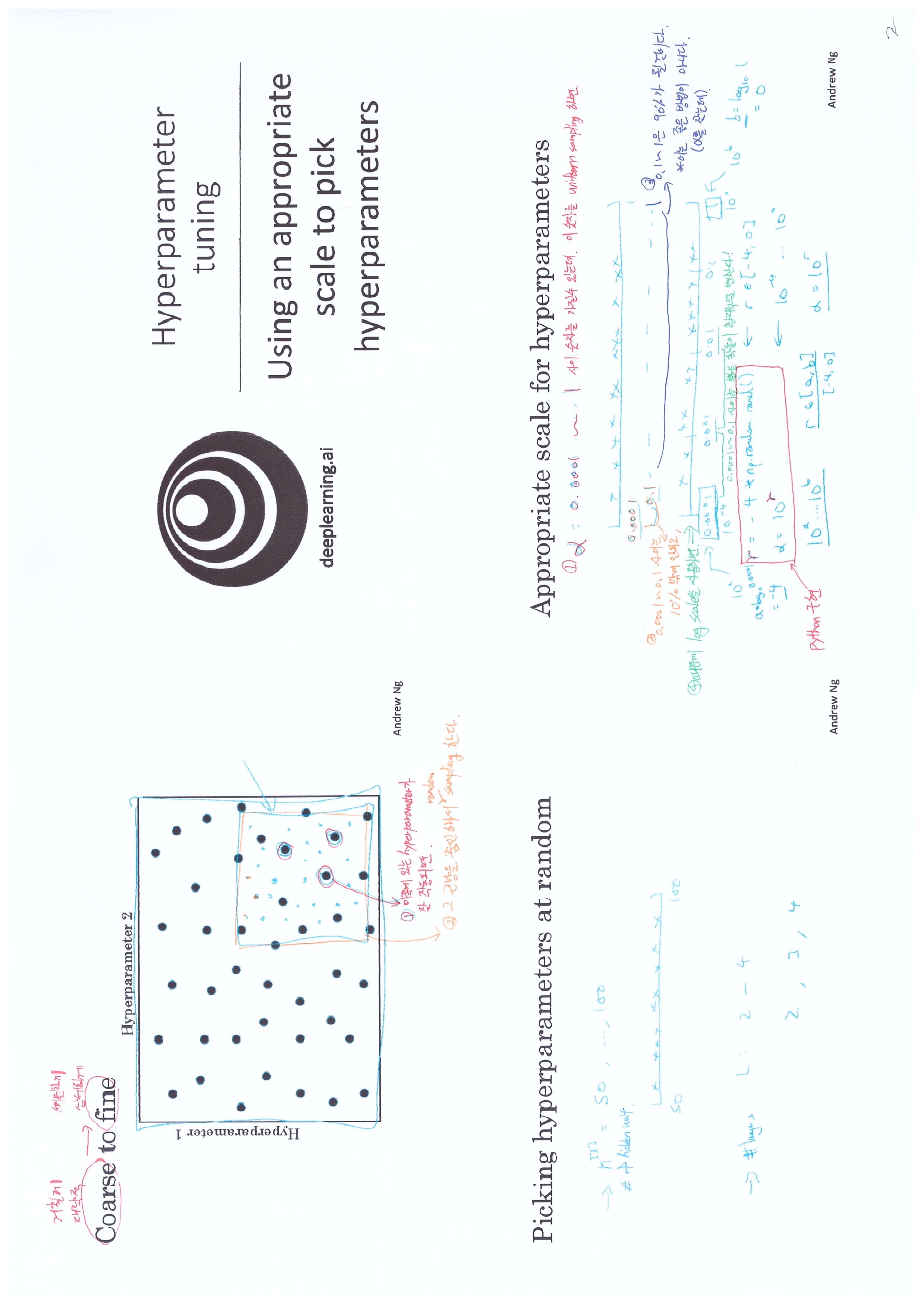
Note
coarse to fine

Note
hyperparameter tuning
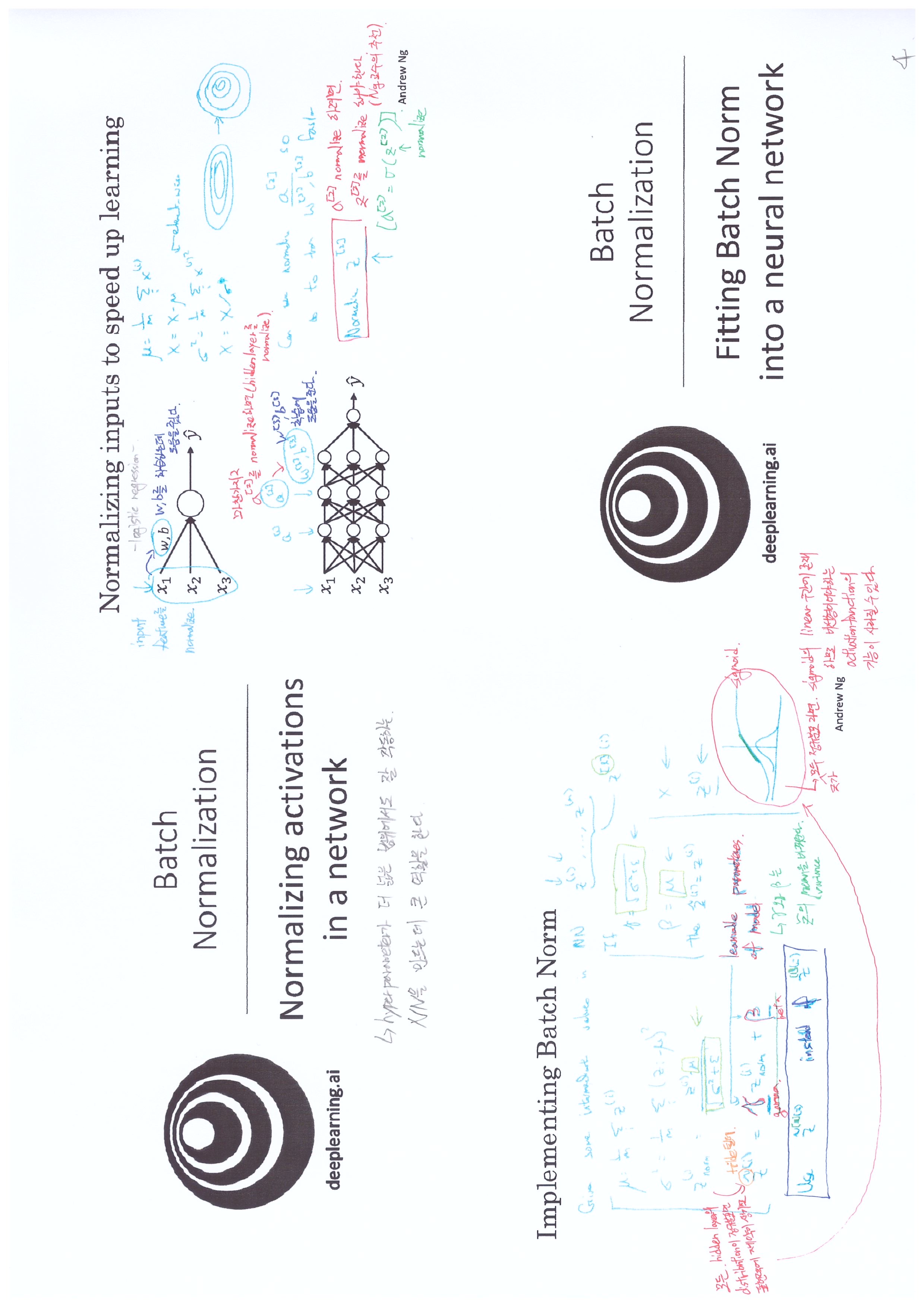
Note
batch normalization,gamma,beta

Note
batch norm,mini batch